【译】Google 出品 - Understand the JavaScript SEO basics
理解 JavaSript SEO 基础
原文 https://developers.google.com/search/docs/guides/javascript-seo-basics
你是否怀疑过由于 JavaScript 的问题可能会影响你的网页或者某一部分内容出现在 Google Search 的结果? 你通过我们的故障排除指南来了解如何解决 JavaScript 相关的这些问题。
JavaScript 是 WEB 平台中重要的一部分,因为它能够提供由普通 web 网站向功能更强大的应用平台转变的众多特性。开发 JavaScript 驱动的 web 应用可以帮助你吸引新用户,同时可以通过 Google 搜索到你的 web 应用提供出来的有效内容来留存现有用户。当 Google Search 通过 Chromium 引擎来执行 JavaScript 时,你可以做一些下面这些事情去进行优化改进你的 Web 应用。
下面这个指南描述了 Google Search 是如何处理 JavaScript 的,同时也在展示提升 Google Search SEO 结果的最佳实践。
一段油管视频地址
Googlebot 如何处理 JavaScript
Googlebot 处理 JavaScript web 应用存在三个主要阶段:
- Crawling 爬取
- Rendering 渲染呈现
- Indexing 建立索引
Googlebot 爬取,渲染并索引页面的步骤。
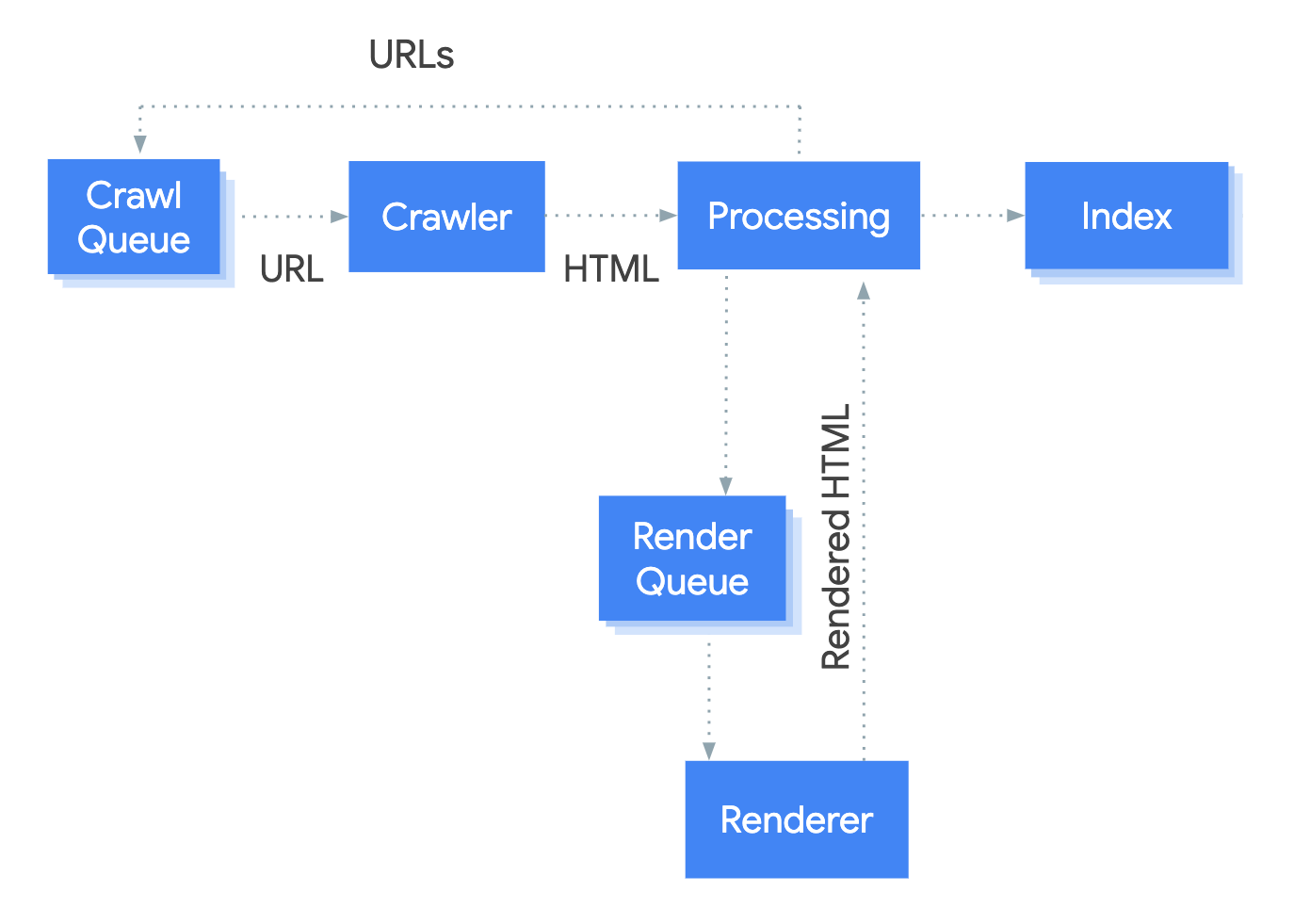
Googlebot 会将网页排入队列,以便爬取和渲染。当页面正在等待被爬取时和正在等待等待渲染时,并不容易被用户立即察觉到。
当 Googlebot 从爬取队列中获取一个 URL 来创建一个 HTTP 请求时,它首先会检查你的网站是否允许被爬取。Googlebot 会阅读 robot.txt 文件。如果它标记了当前 URL 不允许爬取,Googlebot 会跳过对这个 URL 的 HTTP 请求。
Googlebot 会解析在 HTML 链接中的 href 属性转换出来的其他 URL 的响应,同时将这些 URL 放在待爬取的队列中。如果要阻止链接的查找,可以使用 nofollow mechanism。
爬取 URL 时处理 HTML 响应在传统型网站和服务端渲染页面的网站很奏效,服务端渲染网站其中的 HTTP 响应中包含了全部的内容。一些 JavaScript 网站可能会用到 app shell model,这些网站在初始 HTML 内容中并不包含实际的内容,Googlebot 需要在看到十几页面内容之前执行 JavaScript。
Googlebot 将需要渲染的页面排入队列,除非网站的 robots meta tag or header 信息告诉 Googlebot 不要对这个页面进行索引。这个页面可能在队列中短暂停留,但是它将花费更长的时间。一旦 Googlebot 的资源允许,headless Chromium 可以渲染这个页面并且执行 JavaScript。Googlebot 会再次解析渲染完成的 HTML 链接,并且按照队列查找的 URL 继续爬取。Googlebot 也会使用渲染完成的 HTML 对页面进行索引。
请记住,服务端渲染或者预加载仍然是很好的解决方案,因为这个方案可以使你的网站面向用户、爬虫时响应迅速,而不是所有 bots 可以运行 JavaScript。
用唯一的 title 和 snippets 描述网页
唯一的,可描述的标题以及有用的 meta 描述信息可以帮助用户快速地有目的性的定位最佳的搜索结果,我们在指南中解释什么是好的 title 和 description。
你也可以使用 JavaScript 设置或者修改 title 和 meta 描述信息。
Google Search 可以基于用户的查询展示不同的标题和描述。当标题或者说明与页面内容相关性较低,或者我们在页面中发现与搜索结果更匹配的替代方法时,就会发生这种情况。有关标题和说明的代码片段的详细信息,请参与此页面。
编写向下兼容的代码
浏览器提供了很多 API 并且 JavaScript 也是一个快速进化的编程语言。Googlebot 在支持哪些 API 和 JavaScript 功能方面有一些限制。为了确保你的代码可以兼容 Googlebot,请遵循我们的 JavaScript 故障指南。
如果你发现你需要的 API 缺失,我们建议使用不同的服务和 polyfills。如果一些浏览器特性没有被 polyfill 补丁,我们建议你多看 polyfill 文档,了解潜在的限制。
使用有意义的 HTTP 状态码
在爬取页面时,Googlebot 使用 HTTP 状态码识别页面的一些问题。
你可以使用有意义的状态码告诉 Googlebot 当 前页面是否需要被爬取或者索引,比如 404 代表页面已经失联,401 代表登录前的页面。你可以使用 HTTP 状态码告诉 Googlebot 这个页面被转移到一个新的 URL ,因此索引可以被及时更新。
下面是 HTTP 的状态码列表
| HTTP status | When to use |
|---|---|
| 301/302 | 当前页面已经跳转到新 URL |
| 401/403 | 当前页面由于权限问题不可访问 |
| 404/410 | 当前页面不存在 |
| 5xx | 服务端异常 |
使用 meta robot tag
你可以通过 meta robots 标签标记来阻止 Googlebot 对页面标记索引页面。举个例子,在页面中增加下面一个标签:
1 | <!-- Googlebot won't index this page or follow links on this page --> |
当 Googlebot 在 robots meta 标签中遇到 noindex,它就不会渲染或者索引这个页面。
使用 JavaScript 修改或删除
robots meta标签可能不会如期望似的生效。如果 meta 标签包含noindex,Googlebot 会跳过渲染和 JavaScript 执行。如果你想要使用 JavaScript 修改 robots meta 标签,需要设置noindex。
处理图片和懒加载内容
图片加载在宽带和性能方面会带来很大的消耗。一个好的策略是使用延迟加载,仅在用户即将看到图像时加载图片。为了确保更好的实现延迟加载,请遵循我们的延迟加载指南。


